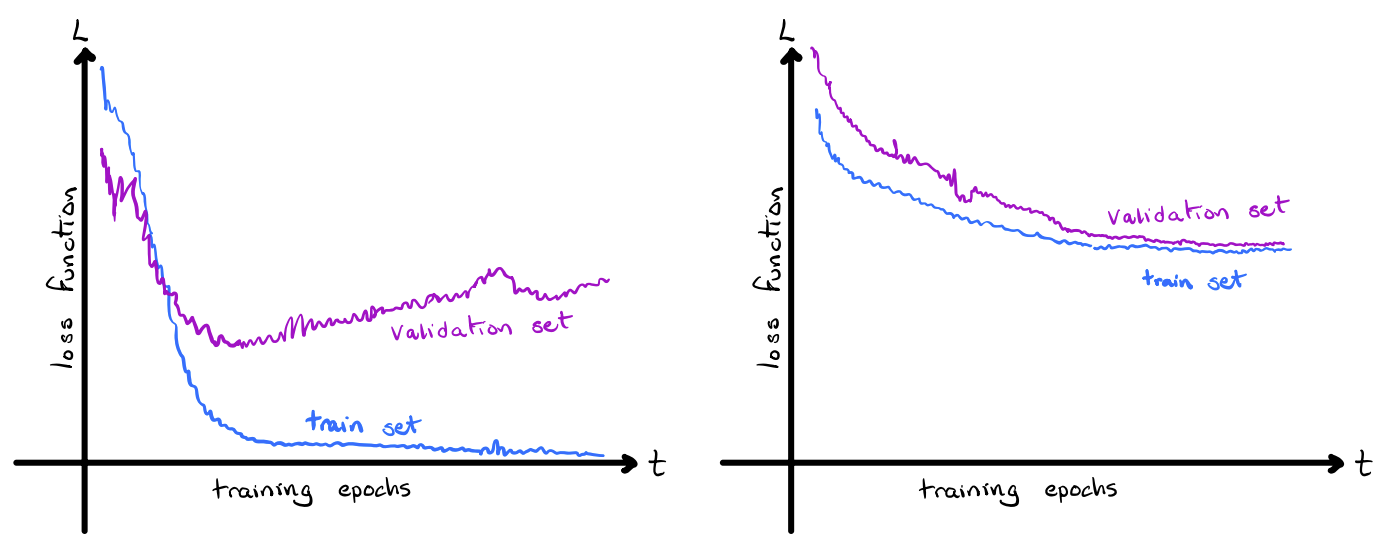
Consider the following pair of plots. Each plot shows the training progress of a model. You may assume that the axis scales and the training data are identical between the plots. The only difference is which model is being trained.
Answer the following questions about these training plots:
In your own words, why is it important to have seperate datasets for training and validation? Which is a better measure of real-world performance?
Intuitively, we often talk about the performance of a model as “accuracy”. But there is no single accuracy formula that applies to all problems. Instead, let’s talk about a “loss function” that measures how good a model’s prediction is.
Suppose we’re doing tracking in video. Our model input is two things: a sequence of video frames, and the pixel location of a feature in the first frame. Our model should return the location of that feature in all of the other frames.
For this problem, write a possible loss function for this problem. There are many answers that could work, but all correct answers will have a few properties: