DEAR VANITY [FAIR], -Just a year ago last Christmas, two young ladies-smarting under that sorest scourge of feminine humanity, the having "nothing to do"-besought me to send them "some riddles." But riddles I had none at hand, and therefore set myself to devise some other form of verbal torture which should serve the same purpose. The result of my meditations was a new kind of Puzzle-new at least to me-which, now that it has been fairly tested by a year's experience and commended by many friends, I offer to you, as a newly-gathered nut, to be cracked by the omnivorous teeth which have already masticated so many of your Double Acrostics. The rules of the Puzzle are simple enough. Two words are proposed, of the same length; and the Puzzle consists in linking these together by interposing other words, each of which shall differ from the next word in one letter only. That is to say, one letter may be changed in one of the given words, then one letter in the word so obtained, and so on, till we arrive at the other given word. The letters must not be interchanged among themselves, but each must keep to its own place. As an example, the word "head" may be changed into "tail" by interposing the words "heal, teal, tell, tall." I call the two given words "a Doublet," the interposed words "Links," and the entire series "a Chain," ... It is perhaps, needless to state that it is de rigeuer that the links should be English words, such as might be used in good society. ... I am told that there is an American game involving a similar principle. I have never seen it, and can only say of its inventors, "pereant qui ante nos nostra dixerunt!"Your task in this assignment will be to build the underlying data structures that will allow you to find a chain of links yielding a solution to Carroll's doublets for any pair of words. In the next assignment, you'll complete the search algorithm and do some preliminary experiments with it.
Create a class called Links that contains such a structure.
The constructor should take a file name as a parameter and call a
private helper method to populate the links data with word information
from the file, which should have one word per line. Include a member
method, getCandidates(), that takes a string and returns a collection of the valid connections
(i.e., candidate plays) from the given word or null if there
are none.
The getCandidates() method in Link must execute in O(1) time. It gets called OFTEN when searching for doublets. For example, it should probably just do an O(1) lookup into a data structure and then check to see if it should return null – most importantly, it can't do any string calculations. Therefore, you will need to do all of the work to figure out the set of words that differ from the given word in the constructor.
Starting from the first doublet, there are many possible links that could lead to a solution. For instance in finding a valid chain for Carroll's doublet from head to tail, you may decide to use a link from head to heal, or you might decide instead to use a link from head to hear.
Which one should you choose? If you are playing cerebrally, you might choose the link that seems most promising. However, it could end up being a dead-end, requiring you to resort to some alternative link.
Computationally, this process requires storing the alternatives you intend perhaps to try later if your search should come up short. Of course, you'd also need a method to retrieve one of those alternatives for examination. This should sound much like the capabilities of two collections you have studied recently featuring slightly different spins on "put one in" and "take one out" capabilities. Because the behavior can differ, we may want to use them interchangeably to guide our search.
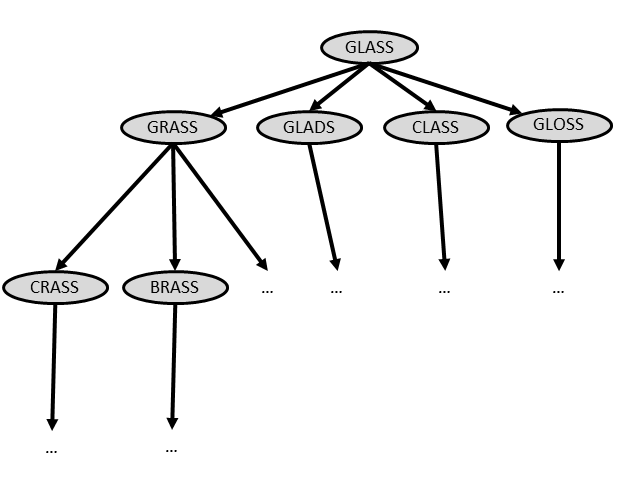
You can visualize the search as a tree:
GLASS has 4 links to candidate words. GRASS has 2 links shown.
Searching for the correct chain just means expanding this tree until we
find the end word. This makes sense if we can expand words in parallel.
But we can't do this; we can only call getCandidates() on one word at a
time. So we need to store the other chains in some kind of data
structure.
Say we wanted to call getCandidates() to examine all the words at depth
= 1 first before looking at anything on level 2: this is called a
breadth-first search. (Can you see why? We search broadly before we go
deep along a path.) What kind of traversal did we call this? What kind
of data structure did we use for the corresponding iterator?
But maybe we think a depth-first search would be quicker. Then we would want to call getCandidates() on the first chain at depth 1 (grass), then call getCandidates() on the first new candidate at depth 2 (crass), then getCandidates() on the first new candidate in level 4, etc. all before expanding any of the other chains at depth 1! What kind of traversal is this? What kind of data structure did we use for the corresponding iterator?
See the difference? In the first case, we expand GLADS before CRASS, but in the second, we expand CRASS before GLADS.
To take advantage of polymorphism, we have given you a ChainManager abstract class that supports two core methods: add, which simply adds a chain for future consideration, and next, which returns (and removes) a chain.
In addition to these, we may be interested in tracking the performance of the manager. We include two other methods, numNexts, which returns the number of times next has been called, and maxSize, which returns the the largest number of chains the manager has stored so far.
With all of the pieces in place from the previous assignment, you are now ready to find a chain of links between doublets. But how? A sketch of the algorithm is as follows.
To get the process started, the initial chain is quite simple: it should contain the start word. This is your current (first) candidate chain.
What should you do with a candidate? First, see whether the last word in the chain is the ending doublet. If it is, the candidate chain is in fact a solution. Otherwise, you'd need to get the allowable linking words of the candidate chain's last word. (This is what you built earlier in the assignment.)
For each of these possible linking words, you'd tell the chain manager that you'd (later) like to consider a new chain (built on the candidate) that has the linking word at the end. Of course, that's only if the linking word is not already in the candidate chain.
Once you've done that, you'd ask the chain manager for the next chain to consider and repeat the process. If the chain manager says there's nothing left, you know there is no chain between the doublets.
Create a class called Doublets whose constructor takes a Link object. Add a member method getChain that takes the two doublet strings (starting and ending) and a ChainManager, returning a solution Chain or null if there is none. This method should implement the algorithm sketched above.
Note: Please don't treat the output above as a unit test: the numbers you get will vary depending on the order you generate links. The relative sizes of candidates, max size, etc are important, though: you should find that each manager has its own strengths and weaknesses.
The stack manager tends to find chains that are unnecessarily long. Meanwhile, the queue manager is guaranteed to find the shortest solution, but can take gobs of memory. Both of these managers somewhat unintelligently choose which candidate to explore next. Can we perhaps do better?
When new chains are added to a queue, they are necessarily at the end. Thus the queue manager returns the candidate with the shortest chain for examination. While this is an advantage, when several chains have the same length, we have no way of distinguishing which may be better. For instance, which of the following two chains would you prefer to be working from for the doublet head/tail?
If you've played the game before, you'd probably pick the first. Why? After five moves, the end of the first chain differs from the goal word by only a single character. By contrast, the end of the second chain differs from the goal word in all four characters. We have an intuitive sense that the first is better. Can we formalize this somehow?
Instead of returning the shortest chain for examination, we would like to return the chain with the shortest total estimated solution length. That is, when a particular incomplete chain is extended to yield a solution, what will the solution's length be? We already know how long the candidate chain is, but how can we estimate how much longer the chain must be to reach the solution? One optimistic estimate is to count the number of characters that differ between the chain's end and the goal word. Because you can only change one character at a time, the remaining chain must have at least this many words in it (though perhaps more).
The value of a chain (for a particular doublet) is thus given by
|
Enter chain manager (s: stack, q: queue, p: priority queue, x: exit): p
PS: once you finish this part, you will have implemented a cornerstone of artificial intelligence (AI): A* search! http://en.wikipedia.org/wiki/A*_search_algorithm (PPS, further along this tangent: In Dr. Boutell's solution of LodeRunner in CSSE220, his Guards used A* search to find the best path to pursue the Hero.)
To enable you to focus on the non-routine parts of this program, we have provided you with a small amount of starting code and two test classes.
In ChainManager.java, we have given you a basic framework and some variable declarations that you may find helpful. Feel free to change anything except the signature of the methods, since we may write test code that calls these directly. You may wish to write additional methods to help with your computations.
There are unit tests for the Link and Chain classes, which are some of the first you'll need to write. After that, you'll test it with your program.
Turn-in your programming work by committing it to your SVN repository. (Of course, you should have committed many times by now). Be sure that your code contains the name(s) of the author(s).
We plan to use this checklist: GradingChecklist_Doublets.doc