CSSE 230
Data Structures and Algorithm Analysis
Homework 9 - 45 points
Reading
In our textbook (link at top of Moodle page), read 3.1-3.3, 3.5-3.8 (and more*).
This is all of chapter 3 (sorting) except 3.4.
Section 3.4, shellsort, is optional but interesting (the runtime isn't O(n2) or
O(nlogn), but O(n3/2)...).
*Plus, section 9.9 isn't required but may be useful to you when doing GraphSurfing Milestone 2.
To Be Turned In
Submit to the drop box.
- (23 points). Average-case analysis of unsuccessful search on a naive binary search tree (i.e., NOT self-balancing. Note: we assume such trees are created using only insertions, not deletions.)
- (Adaptation of Weiss Exercise 19.7.) For an extended binary tree (EBT) T, you know already that internal path length IPL(T) is the sum of the depths of all of the internal nodes of T. Similarly, the external path length,
EPL(T), is defined as the sum of the depths of all of the external nodes of T. Prove that for any EBT T,
EPL(T) = IPL( T) + 2*IN(T),
by strong induction on the number of internal nodes IN(T) in the tree.
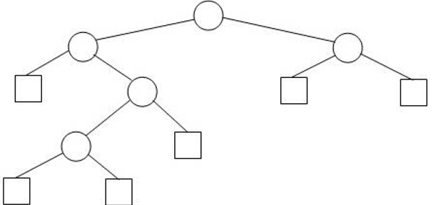
An example of this fact is given by the tree in the following picture: note that IPL(T) = 0+1+1+2+3 = 7, and
EPL(T) = 2+2+2+3+4+4 = 17 = 7 + 2*5 = 7 + 2*IN(T). Your job is to show this relation is true for EBTs in general.
-
In class, we analyzed the average case of successful search on a naive binary search tree. To do this, we derived that the expected IPL(T) [i.e., sum of depths] for a tree T of size IN(T) = N is approximately 1.38 N log N. Dividing this by N, we see the average-case depth of a node, and thus running time for successful search, is O(log N).
Suppose that an unsuccessful search (for a value not in the tree) is equally likely to end in any of the external nodes of the tree. Given this assumption, the successful-search analysis from class, and the result of your proof from (a), what can you say about the average-case big-O running time of an unsuccessful search on a naive BST? Briefly explain your answer.
- (12 points) Solve the recurrence relations below. Indicate
which strategy you are using and show your work. Big-theta or exact
answer required? Big-theta. On any problem where it is appropriate to
use the Master Theorem, big-theta is sufficient (you can't get better
from the theorem). But if the master theorem doesn't apply for a
certain problem (hint, hint), you'll have to use another technique like
telescoping, or filling out a table and doing guess and check. And then
you'll have an exact answer anyway on your way to getting big-theta. So
write the exact answer too as part of your solution.
- T(1) = 1, T(N) = 2 T(N/4)
+ N0.5
- T(1) = 1, T(N) = T(N
- 2) + 2, assuming N is odd.
- T(1) = 1, T(N) = 3 T(N/2)
+ 2N
- (10 points) Suppose that two arrays A and B are sorted and each contain N elements.
Give an O(log N) algorithm to find the median of all elements in A and B.
How to start? Start with a simple example. I recommend two arrays
with an odd number of elements and no duplicates, say [2,4,6] and [8, 10, 12]. Then start to think about
which elements to compare to search quickly. Sketch out an algorithm. Then try to pick a harder example;
if it breaks your algorithm, fix it. Keep going. Finally, realize that duplicates are allowed and
should be accounted for in the median computation: for example, if
A = [1,3,3] and B = [2,3,3], then the answer should be the median of
[1,2,3,3,3,3], which is 3.
You don't need exact Java code, but explain your algorithm in enough detail to
convince us it works in O(Log N) time. This will require some insight -
don't leave it to the last minute!